如何本地搭建 RAG 知识库
一、开篇:当大模型遇到知识边界
首先解释下什么是 LLMOps,Large Language Model Operations是专注于大语言模型全生命周期管理的工程实践,涵盖从模型开发、部署、监控到持续优化的系统性流程。其核心目标是提升LLM应用的可靠性、效率与可控性,解决大模型在实际落地中的技术与管理挑战。
那什么是 RAG 呢? RAG 即检索增强生成(Retrieval Augmented Generation),它结合了信息检索和大语言模型(LLM)的能力,有效地解决了大语言模型知识更新不及时、缺乏特定领域信息等问题。
传统的大语言模型虽然具备强大的语言理解和生成能力,但它的知识是基于训练数据的,存在一定的时效性和局限性。RAG 的核心思想是在大语言模型生成回答之前,先从外部知识库中检索与用户问题相关的信息,然后将这些信息作为额外的上下文提供给大语言模型,帮助其生成更准确、更有针对性的回答——通用大模型本质是概率生成器,而企业需要的是能精确调用领域知识的"增强型大脑"。
二、RAG 实现流程概述

2.1 数据准备
收集数据:确定所需的知识领域,收集相关的文本数据,如文档、文章、报告、网页等。这些数据可以来自企业内部的知识库、公开的数据集、专业的文献库等。
数据清洗和预处理:对收集到的数据进行清洗,去除噪声、重复数据和无效信息。然后进行预处理,如分词、词性标注、命名实体识别等,以便后续的索引和检索。
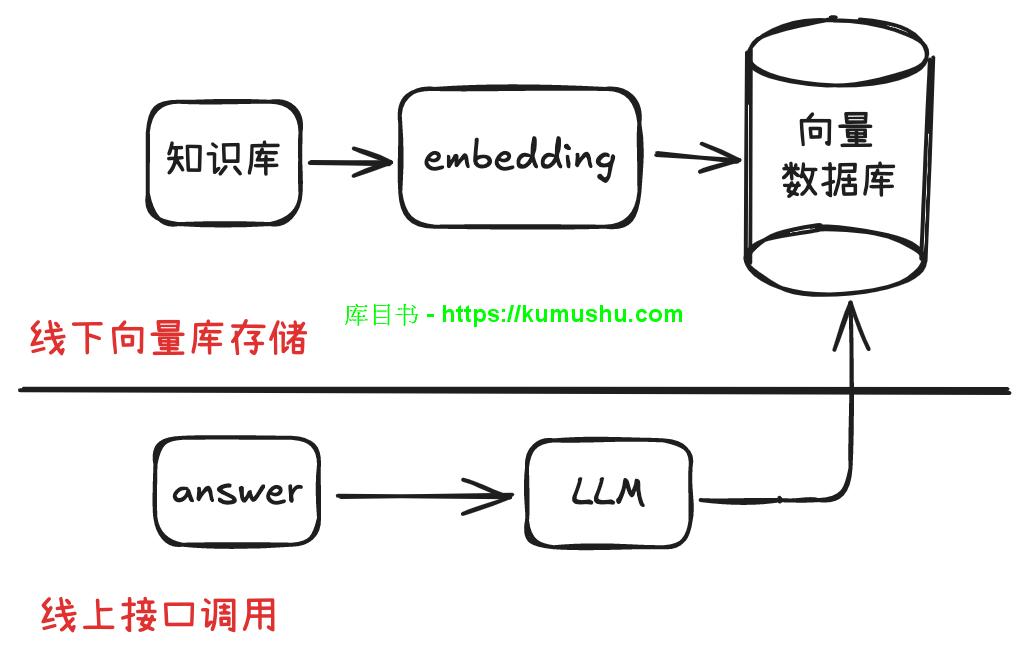
2.2 构建向量数据库
文本向量化:使用文本嵌入模型(如 OpenAI 的 text-embedding-ada-002、BGE-M3 等)将预处理后的文本数据转换为向量表示。这些向量能够捕捉文本的语义信息,使语义相近的文本在向量空间中距离更近,至于怎么相近需要理解 transformer 自注意力机制原理,后面会讲到。
存储向量:将生成的向量存储到向量数据库中,如 Pinecone、Milvus 等。向量数据库支持高效的向量相似度搜索,能够快速找到与查询向量最相似的向量。
2.3 检索模块
用户查询向量化:当用户提出问题时,将问题文本转换为向量,使用的嵌入模型(embedding 模型) 要与构建向量数据库时一致。
相似度搜索:在向量数据库中进行相似度搜索,找到与用户查询向量最相似的向量对应的文本片段。通常使用余弦相似度等度量方法来计算向量之间的相似度。
筛选和排序:对检索到的文本片段进行筛选和排序,选择最相关、最有价值的信息作为上下文。可以根据相似度得分、文本的权威性、时效性等因素进行筛选和排序
2.4 生成模块
提供上下文:将筛选后的文本片段作为额外的上下文与用户的问题一起输入到大语言模型中。
生成回答:大语言模型根据输入的问题和上下文信息,生成相应的回答。大语言模型可以是开源的(如 deepseek、Llama 3、ChatGLM 等)或商业的(如 豆包、 GPT-4、通义千问等)。
2.5 后处理
答案优化:对大语言模型生成的回答进行优化,如检查语法错误、调整表述方式、去除不必要的信息等,以提高回答的质量。
评估和反馈:对生成的回答进行评估,如使用人工评估或自动评估指标(如准确率、召回率、F1 值等)来衡量回答的质量。根据评估结果,对检索和生成过程进行调整和优化,以不断提高系统的性能。
三、RAG核心原理

2.1 架构三要素:检索-生成-修正
如果把RAGFlow比作一个智能问答系统,它的工作流程可以拆解为三个核心环节:
检索层:像图书馆管理员,根据用户问题快速定位相关文档
生成层:扮演作家角色,基于检索结果创作回答
修正层:担任校对编辑,确保内容准确合规
这三者的协作关系可以用一个形象的比喻说明:
检索层是"眼睛",负责找到关键信息
生成层是"嘴巴",负责组织语言表达
修正层是"大脑",负责逻辑校验
2.2 向量检索的数学魔法
在RAGFlow中,所有文档都会被转化为数字向量。这个过程就像给每个词语发一张"身份证",比如"人工智能"可能对应[0.8, -0.3, 0.5]这样的坐标,先简单理解,后面单独讲解向量过程。
当用户提问时,系统会做三件事:
将问题转换为向量(问题向量)
在向量数据库中查找最相似的文档向量
提取对应文档作为回答依据
这里的相似度计算采用余弦相似度公式:
cosθ = (A·B) / (|A| × |B|)
当两个向量夹角趋近于0时,相似度趋近于1,意味着语义高度相关。
2.3 生成模型的增强策略与传统生成模型的区别
维度 | 传统生成模型(如GPT) | RAG |
|---|---|---|
知识来源 | 依赖训练时的静态知识 | 动态检索外部知识库 |
可解释性 | 黑箱生成,难以追踪依据 | 可追溯引用文档,解释性强 |
更新成本 | 需重新训练或微调 | 仅更新知识库,无需动模型 |
长尾问题 | 对训练未覆盖的问题易产生幻觉 | 通过检索补充知识,减少幻觉 |
适用场景 | 通用对话、创意生成 | 专业领域(医疗、法律)、事实性问答 |
2.4 核心优势
动态知识注入:知识库可实时更新(如添加最新新闻、产品文档、最新更新的制度、政策文件等)。
降低训练成本:无需为特定领域重新训练大模型。
可控性与安全:将 embedding 过程和向量数据库存储在本地,通过接口调用 LLM 做检索输出,大大提高原始数据的安全性。
创建一个使用Spring AI框架构建RAG(Retrieval-Augmented Generation)系统的案例。这个案例将演示如何构建一个智能文档问答系统。
项目概述
我们将构建一个基于Spring AI的RAG系统,它可以:
摄取和处理文档(PDF、文本等)
将文档分割成chunks并向量化存储
根据用户问题检索相关文档片段
结合检索到的上下文生成准确回答
1. 项目依赖配置
首先创建Maven项目,添加以下依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>spring-ai-rag-demo</artifactId>
<version>1.0.0</version>
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<spring-ai.version>0.8.0</spring-ai.version>
</properties>
<dependencies>
<!-- Spring Boot Starters -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Core -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- Vector Store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- Document Readers -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<!-- Text Splitters -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-transformers</artifactId>
<version>${spring-ai.version}</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>2. 配置文件
创建 application.yml:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
chat:
options:
model: gpt-3.5-turbo
temperature: 0.7
embedding:
options:
model: text-embedding-ada-002
vectorstore:
chroma:
url: http://localhost:8000
collection-name: documents
server:
port: 8080
logging:
level:
org.springframework.ai: DEBUG3. 核心配置类
package com.example.rag.config;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.reader.pdf.PdfDocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.chroma.ChromaVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class RagConfiguration {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
@Bean
public TokenTextSplitter textSplitter() {
return new TokenTextSplitter(500, 100, 5, 10000, true);
}
@Bean
public VectorStore vectorStore(EmbeddingClient embeddingClient) {
return new ChromaVectorStore(embeddingClient, "http://localhost:8000", "documents", true);
}
}4. 文档处理服务
package com.example.rag.service;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.pdf.PdfDocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.StandardCopyOption;
import java.util.List;
import java.util.Map;
@Service
public class DocumentService {
@Autowired
private VectorStore vectorStore;
@Autowired
private TokenTextSplitter textSplitter;
/**
* 处理并存储文档
*/
public String processDocument(MultipartFile file) throws IOException {
// 保存上传的文件到临时位置
Path tempFile = Files.createTempFile("upload-", file.getOriginalFilename());
Files.copy(file.getInputStream(), tempFile, StandardCopyOption.REPLACE_EXISTING);
try {
// 选择合适的文档读取器
DocumentReader reader = createDocumentReader(tempFile, file.getOriginalFilename());
// 读取文档
List<Document> documents = reader.get();
// 为每个文档添加元数据
documents.forEach(doc -> {
Map<String, Object> metadata = doc.getMetadata();
metadata.put("source", file.getOriginalFilename());
metadata.put("upload_time", System.currentTimeMillis());
});
// 分割文档
List<Document> splitDocuments = textSplitter.apply(documents);
// 存储到向量数据库
vectorStore.add(splitDocuments);
return String.format("成功处理文档: %s, 生成了 %d 个文档片段",
file.getOriginalFilename(), splitDocuments.size());
} finally {
// 清理临时文件
Files.deleteIfExists(tempFile);
}
}
/**
* 根据文件类型创建相应的文档读取器
*/
private DocumentReader createDocumentReader(Path filePath, String filename) {
Resource resource = new org.springframework.core.io.FileSystemResource(filePath.toFile());
if (filename.toLowerCase().endsWith(".pdf")) {
return new PdfDocumentReader(resource);
} else {
// 对于其他文件类型,使用Tika读取器
return new TikaDocumentReader(resource);
}
}
/**
* 批量处理文档
*/
public String processBatchDocuments(List<MultipartFile> files) {
StringBuilder result = new StringBuilder();
int successCount = 0;
int totalChunks = 0;
for (MultipartFile file : files) {
try {
String processResult = processDocument(file);
result.append(processResult).append("\n");
successCount++;
// 提取chunk数量
String[] parts = processResult.split("生成了 ");
if (parts.length > 1) {
String chunkInfo = parts[1].split(" ")[0];
totalChunks += Integer.parseInt(chunkInfo);
}
} catch (Exception e) {
result.append(String.format("处理文档 %s 失败: %s\n",
file.getOriginalFilename(), e.getMessage()));
}
}
result.append(String.format("\n批处理完成: 成功处理 %d/%d 个文件,总共生成 %d 个文档片段",
successCount, files.size(), totalChunks));
return result.toString();
}
}5. RAG查询服务
package com.example.rag.service;
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Service
public class RagService {
@Autowired
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
private static final String SYSTEM_PROMPT_TEMPLATE = """
你是一个智能助手,专门根据提供的上下文信息回答用户问题。
请遵循以下规则:
1. 仅基于提供的上下文信息回答问题
2. 如果上下文中没有相关信息,请明确说明
3. 保持回答准确、简洁且有帮助
4. 如果可能,引用具体的信息来源
上下文信息:
{context}
请基于以上上下文回答用户的问题。
""";
/**
* 执行RAG查询
*/
public RagResponse query(String question, int maxResults) {
// 1. 检索相关文档
List<Document> relevantDocuments = retrieveRelevantDocuments(question, maxResults);
if (relevantDocuments.isEmpty()) {
return new RagResponse(
"抱歉,我在知识库中没有找到与您的问题相关的信息。请尝试重新表述问题或上传相关文档。",
List.of(),
question
);
}
// 2. 构建上下文
String context = buildContext(relevantDocuments);
// 3. 生成回答
String answer = generateAnswer(question, context);
// 4. 准备源信息
List<DocumentInfo> sources = relevantDocuments.stream()
.map(this::extractDocumentInfo)
.collect(Collectors.toList());
return new RagResponse(answer, sources, question);
}
/**
* 检索相关文档
*/
private List<Document> retrieveRelevantDocuments(String question, int maxResults) {
SearchRequest searchRequest = SearchRequest.query(question)
.withTopK(maxResults)
.withSimilarityThreshold(0.7);
return vectorStore.similaritySearch(searchRequest);
}
/**
* 构建上下文字符串
*/
private String buildContext(List<Document> documents) {
return documents.stream()
.map(doc -> {
String source = doc.getMetadata().get("source") != null ?
doc.getMetadata().get("source").toString() : "未知来源";
return String.format("来源:%s\n内容:%s\n", source, doc.getContent());
})
.collect(Collectors.joining("\n---\n"));
}
/**
* 生成回答
*/
private String generateAnswer(String question, String context) {
Map<String, Object> promptParams = new HashMap<>();
promptParams.put("context", context);
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(SYSTEM_PROMPT_TEMPLATE);
Message systemMessage = systemPromptTemplate.createMessage(promptParams);
UserMessage userMessage = new UserMessage(question);
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
ChatResponse response = chatClient.call(prompt);
return response.getResult().getOutput().getContent();
}
/**
* 提取文档信息
*/
private DocumentInfo extractDocumentInfo(Document document) {
Map<String, Object> metadata = document.getMetadata();
String source = metadata.get("source") != null ?
metadata.get("source").toString() : "未知来源";
String preview = document.getContent().length() > 200 ?
document.getContent().substring(0, 200) + "..." :
document.getContent();
return new DocumentInfo(source, preview, metadata);
}
/**
* 智能搜索 - 返回相关文档片段
*/
public List<DocumentInfo> searchDocuments(String query, int maxResults) {
List<Document> documents = retrieveRelevantDocuments(query, maxResults);
return documents.stream()
.map(this::extractDocumentInfo)
.collect(Collectors.toList());
}
// 内部类定义
public static class RagResponse {
private final String answer;
private final List<DocumentInfo> sources;
private final String originalQuestion;
public RagResponse(String answer, List<DocumentInfo> sources, String originalQuestion) {
this.answer = answer;
this.sources = sources;
this.originalQuestion = originalQuestion;
}
// Getters
public String getAnswer() { return answer; }
public List<DocumentInfo> getSources() { return sources; }
public String getOriginalQuestion() { return originalQuestion; }
}
public static class DocumentInfo {
private final String source;
private final String preview;
private final Map<String, Object> metadata;
public DocumentInfo(String source, String preview, Map<String, Object> metadata) {
this.source = source;
this.preview = preview;
this.metadata = metadata;
}
// Getters
public String getSource() { return source; }
public String getPreview() { return preview; }
public Map<String, Object> getMetadata() { return metadata; }
}
}6. REST API控制器
package com.example.rag.controller;
import com.example.rag.service.DocumentService;
import com.example.rag.service.RagService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
@RestController
@RequestMapping("/api/rag")
@CrossOrigin(origins = "*")
public class RagController {
@Autowired
private DocumentService documentService;
@Autowired
private RagService ragService;
/**
* 上传单个文档
*/
@PostMapping("/upload")
public ResponseEntity<String> uploadDocument(@RequestParam("file") MultipartFile file) {
try {
if (file.isEmpty()) {
return ResponseEntity.badRequest().body("文件不能为空");
}
String result = documentService.processDocument(file);
return ResponseEntity.ok(result);
} catch (Exception e) {
return ResponseEntity.internalServerError()
.body("文档处理失败: " + e.getMessage());
}
}
/**
* 批量上传文档
*/
@PostMapping("/upload/batch")
public ResponseEntity<String> uploadBatchDocuments(
@RequestParam("files") List<MultipartFile> files) {
try {
if (files.isEmpty()) {
return ResponseEntity.badRequest().body("文件列表不能为空");
}
String result = documentService.processBatchDocuments(files);
return ResponseEntity.ok(result);
} catch (Exception e) {
return ResponseEntity.internalServerError()
.body("批量文档处理失败: " + e.getMessage());
}
}
/**
* RAG问答
*/
@PostMapping("/query")
public ResponseEntity<RagService.RagResponse> query(
@RequestBody QueryRequest request) {
try {
if (request.getQuestion() == null || request.getQuestion().trim().isEmpty()) {
return ResponseEntity.badRequest().build();
}
int maxResults = request.getMaxResults() > 0 ? request.getMaxResults() : 5;
RagService.RagResponse response = ragService.query(request.getQuestion(), maxResults);
return ResponseEntity.ok(response);
} catch (Exception e) {
return ResponseEntity.internalServerError().build();
}
}
/**
* 文档搜索
*/
@GetMapping("/search")
public ResponseEntity<List<RagService.DocumentInfo>> searchDocuments(
@RequestParam String query,
@RequestParam(defaultValue = "10") int maxResults) {
try {
List<RagService.DocumentInfo> results = ragService.searchDocuments(query, maxResults);
return ResponseEntity.ok(results);
} catch (Exception e) {
return ResponseEntity.internalServerError().build();
}
}
// 请求对象类
public static class QueryRequest {
private String question;
private int maxResults = 5;
// Constructors, getters, setters
public QueryRequest() {}
public String getQuestion() { return question; }
public void setQuestion(String question) { this.question = question; }
public int getMaxResults() { return maxResults; }
public void setMaxResults(int maxResults) { this.maxResults = maxResults; }
}
}7. 主应用程序类
package com.example.rag;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SpringAiRagApplication {
public static void main(String[] args) {
SpringApplication.run(SpringAiRagApplication.class, args);
}
}启动Chroma向量数据库
# 使用Docker启动Chroma
docker run -p 8000:8000 chromadb/chroma环境变量设置
export OPENAI_API_KEY=your_openai_api_key_hereAPI使用示例
上传文档:
curl -X POST -F "file=@document.pdf" http://localhost:8080/api/rag/upload问答查询:
curl -X POST http://localhost:8080/api/rag/query -H "Content-Type: application/json" -d '{"question": "这个文档主要讲了什么内容?", "maxResults": 5}'
文档搜索:
curl "http://localhost:8080/api/rag/search?query=人工智能&maxResults=10"9. 前端集成示例(HTML + JavaScript)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Spring AI RAG Demo</title>
<style>
body { font-family: Arial, sans-serif; max-width: 800px; margin: 0 auto; padding: 20px; }
.section { margin: 20px 0; padding: 20px; border: 1px solid #ddd; border-radius: 5px; }
.response { background-color: #f5f5f5; padding: 15px; margin: 10px 0; border-radius: 5px; }
.sources { margin-top: 15px; }
.source-item { background-color: #e9ecef; padding: 10px; margin: 5px 0; border-radius: 3px; }
input, textarea, button { width: 100%; padding: 10px; margin: 5px 0; }
button { background-color: #007bff; color: white; border: none; cursor: pointer; }
button:hover { background-color: #0056b3; }
</style>
</head>
<body>
<h1>Spring AI RAG 智能问答系统</h1>
<!-- 文档上传 -->
<div>
<h2>上传文档</h2>
<input type="file" id="fileInput" multiple accept=".pdf,.txt,.doc,.docx">
<button onclick="uploadDocuments()">上传文档</button>
<div id="uploadResult"></div>
</div>
<!-- 问答界面 -->
<div>
<h2>智能问答</h2>
<textarea id="questionInput" rows="3" placeholder="请输入您的问题..."></textarea>
<button onclick="askQuestion()">提问</button>
<div id="answerResult"></div>
</div>
<script>
const API_BASE = 'http://localhost:8080/api/rag';
async function uploadDocuments() {
const fileInput = document.getElementById('fileInput');
const files = fileInput.files;
if (files.length === 0) {
alert('请选择要上传的文件');
return;
}
const formData = new FormData();
for (let i = 0; i < files.length; i++) {
formData.append('files', files[i]);
}
try {
const response = await fetch(`${API_BASE}/upload/batch`, {
method: 'POST',
body: formData
});
const result = await response.text();
document.getElementById('uploadResult').innerHTML =
`<div>${result}</div>`;
} catch (error) {
document.getElementById('uploadResult').innerHTML =
`<div>上传失败: ${error.message}</div>`;
}
}
async function askQuestion() {
const question = document.getElementById('questionInput').value.trim();
if (!question) {
alert('请输入问题');
return;
}
try {
const response = await fetch(`${API_BASE}/query`, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
question: question,
maxResults: 5
})
});
const result = await response.json();
displayAnswer(result);
} catch (error) {
document.getElementById('answerResult').innerHTML =
`<div>查询失败: ${error.message}</div>`;
}
}
function displayAnswer(result) {
let html = `<div>
<h3>回答:</h3>
<p>${result.answer}</p>
</div>`;
if (result.sources && result.sources.length > 0) {
html += '<div><h4>参考来源:</h4>';
result.sources.forEach((source, index) => {
html += `<div>
<strong>来源 ${index + 1}: ${source.source}</strong>
<p>${source.preview}</p>
</div>`;
});
html += '</div>';
}
document.getElementById('answerResult').innerHTML = html;
}
</script>
</body>
</html>总结
这个代码的Spring AI RAG案例展示了:
文档处理:支持PDF、文本等多种格式的文档上传和处理
向量存储:使用Chroma作为向量数据库存储文档embeddings
智能检索:基于语义相似性检索相关文档片段
智能生成:结合检索到的上下文生成准确回答
RESTful API:提供完整的HTTP API接口
前端集成:包含简单的Web界面进行交互